Questions
FINTECH 540.01.Fa25 Final Exam
Single choice
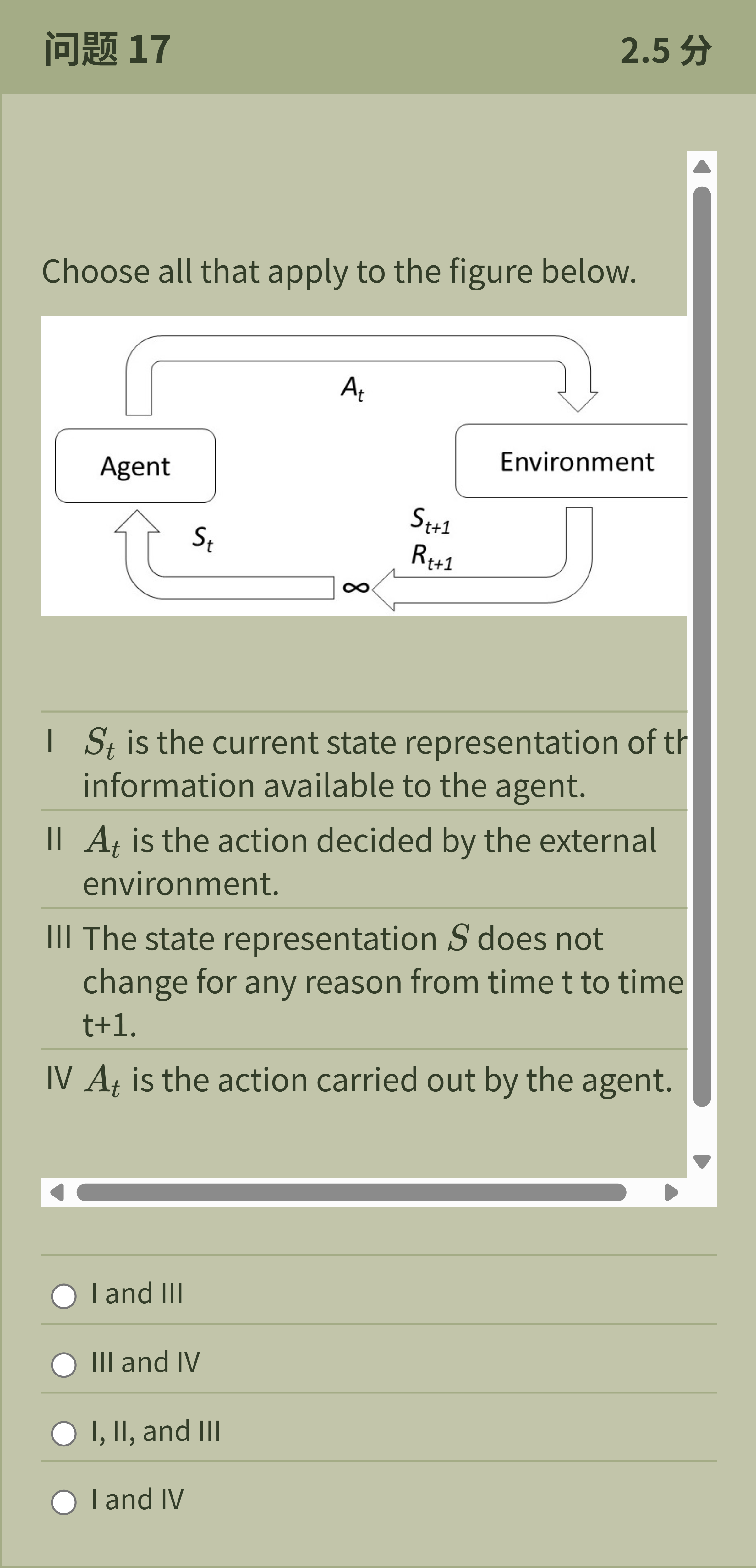
Choose all that apply to the figure below. I 𝑆 𝑡 is the current state representation of the information available to the agent. II 𝐴 𝑡 is the action decided by the external environment. III The state representation 𝑆 does not change for any reason from time t to time t+1. IV 𝐴 𝑡 is the action carried out by the agent.
Options
A.I and III
B.III and IV
C.I, II, and III
D.I and IV
View Explanation
Verified Answer
Please login to view
Step-by-Step Analysis
The question asks which statements apply to the figure showing a typical agent–environment interaction.
Option I: 'S_t is the current state representation of the information available to the agent.' This is correct because the diagram labels S_t as the in......Login to view full explanationLog in for full answers
We've collected over 50,000 authentic exam questions and detailed explanations from around the globe. Log in now and get instant access to the answers!
Similar Questions
Shown is the Q Actor-Critic (QAC) function, with line numbers. 1. Initialise 𝑠 , 𝜃 2. Sample 𝑎 ∼ 𝜋 𝜃 3. for each step do 4. Sample reward 𝑟 = 𝑅 𝑠 𝑎 ; sample transition 𝑠 ′ ∼ 𝑃 𝑠 , ⋅ 𝑎 5. Sample action 𝑎 ′ ∼ 𝜋 𝜃 ( 𝑠 ′ , 𝑎 ′ ) 6. 𝛿 = 𝑟 + 𝛾 𝑄 𝑤 ( 𝑠 ′ , 𝑎 ′ ) − 𝑄 𝑤 ( 𝑠 , 𝑎 ) 7. 𝜃 ← 𝜃 + 𝛼 ∇ 𝜃 𝑙 𝑜 𝑔 𝜋 𝜃 ( 𝑠 , 𝑎 ) 𝑄 𝑤 ( 𝑠 , 𝑎 ) 8. 𝑤 ← 𝑤 + 𝛽 𝛿 𝜙 ( 𝑠 , 𝑎 ) 9. 𝑎 ← 𝑎 ′ , 𝑠 ← 𝑠 ′ 10. end for Which of the following statements is true (can be more than one)?
The value of an action 𝑞 𝜋 ( 𝑠 , 𝑎 ) depends on the expected next reward and the expected value of the next state. We can think of this in terms of a small backup diagram, as follows: Let 𝑃 ( 𝑠 ′ | 𝑠 , 𝑎 ) be the transition probability and 𝑟 ¯ ( 𝑠 , 𝑎 , 𝑠 ′ ) = 𝐸 [ 𝑅 𝑡 + 1 | 𝑆 𝑡 = 𝑠 , 𝐴 𝑡 = 𝑎 , 𝑆 𝑡 + 1 = 𝑠 ′ ] the expected reward for the transion from state 𝑠 to state 𝑠 ′ via action 𝑎 . Rearrange the definition of 𝑞 𝜋 ( 𝑠 , 𝑎 ) in terms of these quantities, such that no expected-value notation appears in the equation. A. 𝑞 𝜋 ( 𝑠 , 𝑎 ) = ∑ 𝑠 ′ 𝑃 ( 𝑠 ′ ∣ 𝑠 , 𝑎 ) [ 𝑟 ¯ ( 𝑠 , 𝑎 , 𝑠 ′ ) + 𝛾 𝑞 𝜋 ( 𝑠 ′ , 𝑎 ) ] B. 𝑞 𝜋 ( 𝑠 , 𝑎 ) = ∑ 𝑠 ′ [ 𝑟 ¯ ( 𝑠 , 𝑎 , 𝑠 ′ ) + 𝛾 ] 𝑃 ( 𝑠 ′ ∣ 𝑠 , 𝑎 ) 𝑣 𝜋 ( 𝑠 ′ ) C. 𝑞 𝜋 ( 𝑠 , 𝑎 ) = ∑ 𝑠 ′ 𝑃 ( 𝑠 ′ | 𝑠 , 𝑎 ) [ 𝑟 ¯ ( 𝑠 , 𝑎 , 𝑠 ′ ) + 𝛾 𝑣 𝜋 ( 𝑠 ′ ) ] D. 𝑞 𝜋 ( 𝑠 , 𝑎 ) = 𝑃 [ 𝑠 ′ ∣ 𝑠 , 𝑎 ] [ 𝑟 ¯ ( 𝑠 , 𝑎 , 𝑠 ′ ) + 𝛾 𝑣 𝜋 ( 𝑠 ′ ) ]
Which statement best describes the difference between SARSA and Q-learning?
Which of the following best describes a key difference between Monte Carlo and Temporal-Difference (TD) learning?
More Practical Tools for Students Powered by AI Study Helper
Making Your Study Simpler
Join us and instantly unlock extensive past papers & exclusive solutions to get a head start on your studies!