Questions
Single choice
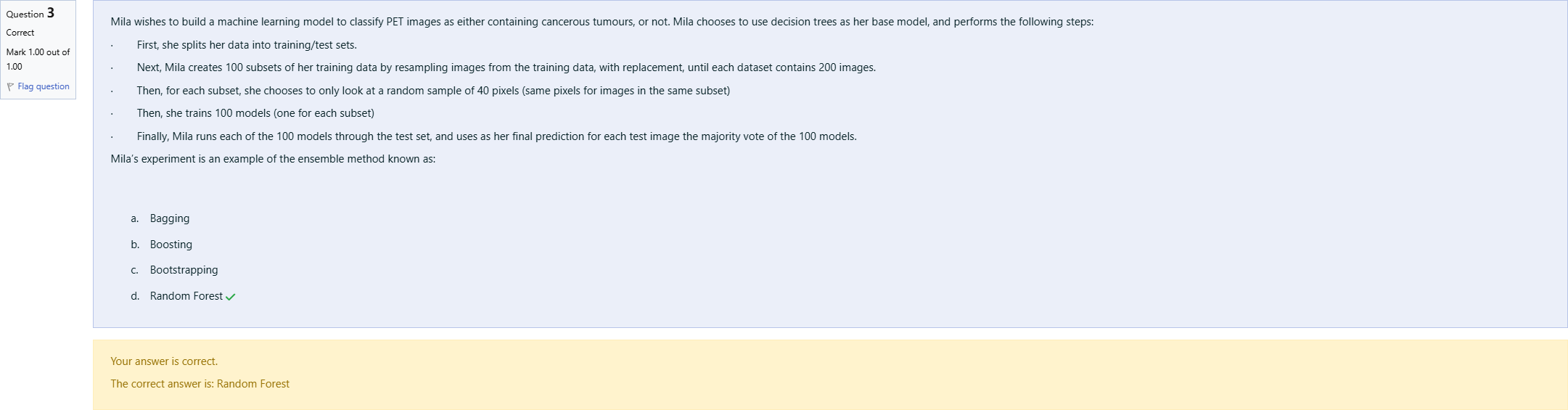
Mila wishes to build a machine learning model to classify PET images as either containing cancerous tumours, or not. Mila chooses to use decision trees as her base model, and performs the following steps: · First, she splits her data into training/test sets. · Next, Mila creates 100 subsets of her training data by resampling images from the training data, with replacement, until each dataset contains 200 images. · Then, for each subset, she chooses to only look at a random sample of 40 pixels (same pixels for images in the same subset) · Then, she trains 100 models (one for each subset) · Finally, Mila runs each of the 100 models through the test set, and uses as her final prediction for each test image the majority vote of the 100 models. Mila’s experiment is an example of the ensemble method known as:
View Explanation
Verified Answer
Please login to view
Step-by-Step Analysis
To analyze the ensemble method described, I will evaluate each option in turn and map it to the steps Mila performed.
Option a: Bagging. Bagging ( bootstrap aggregating ) involves training multiple base models on bootstrapped samples and aggregating their predictions, typically by voting or averaging. While Mila does use bootstrapped samples and majority voting, bagging on its own does not include the additional randomness introduced by selecting a random subset of featu......Login to view full explanationLog in for full answers
We've collected over 50,000 authentic exam questions and detailed explanations from around the globe. Log in now and get instant access to the answers!
Similar Questions
Your bank wants to build a system that automatically approves or denies small consumer loans. Analysts have a historical dataset with applicant age, income, marital status, and number of dependents, along with a labeled outcome (“good” vs. “bad” borrower). The team is considering using either a single decision tree or a random forest, and they show you the decision tree diagram below as an example of how the logic works. Which model should the bank choose if they want higher accuracy and more stability in predictions, especially when detecting risky or fraudulent applications?
Mila wishes to build a machine learning model to classify PET images as either containing cancerous tumours, or not. Mila chooses to use decision trees as her base model, and performs the following steps: · First, she splits her data into training/test sets. · Next, Mila creates 100 subsets of her training data by resampling images from the training data, with replacement, until each dataset contains 200 images. · Then, for each subset, she chooses to only look at a random sample of 40 pixels (same pixels for images in the same subset) · Then, she trains 100 models (one for each subset) · Finally, Mila runs each of the 100 models through the test set, and uses as her final prediction for each test image the majority vote of the 100 models. Mila’s experiment is an example of the ensemble method known as:
Mila wishes to build a machine learning model to classify PET images as either containing cancerous tumours, or not. Mila chooses to use decision trees as her base model, and performs the following steps: · First, she splits her data into training/test sets. · Next, Mila creates 100 subsets of her training data by resampling images from the training data, with replacement, until each dataset contains 200 images. · Then, for each subset, she chooses to only look at a random sample of 40 pixels (same pixels for images in the same subset) · Then, she trains 100 models (one for each subset) · Finally, Mila runs each of the 100 models through the test set, and uses as her final prediction for each test image the majority vote of the 100 models. Mila’s experiment is an example of the ensemble method known as:
Mila wishes to build a machine learning model to classify PET images as either containing cancerous tumours, or not. Mila chooses to use decision trees as her base model, and performs the following steps: · First, she splits her data into training/test sets. · Next, Mila creates 100 subsets of her training data by resampling images from the training data, with replacement, until each dataset contains 200 images. · Then, for each subset, she chooses to only look at a random sample of 40 pixels (same pixels for images in the same subset) · Then, she trains 100 models (one for each subset) · Finally, Mila runs each of the 100 models through the test set, and uses as her final prediction for each test image the majority vote of the 100 models. Mila’s experiment is an example of the ensemble method known as:
More Practical Tools for Students Powered by AI Study Helper
Making Your Study Simpler
Join us and instantly unlock extensive past papers & exclusive solutions to get a head start on your studies!