Questions
IS 4487-006 Fall 2025 Final Exam December 10 from 10:30 to 12:30
Single choice
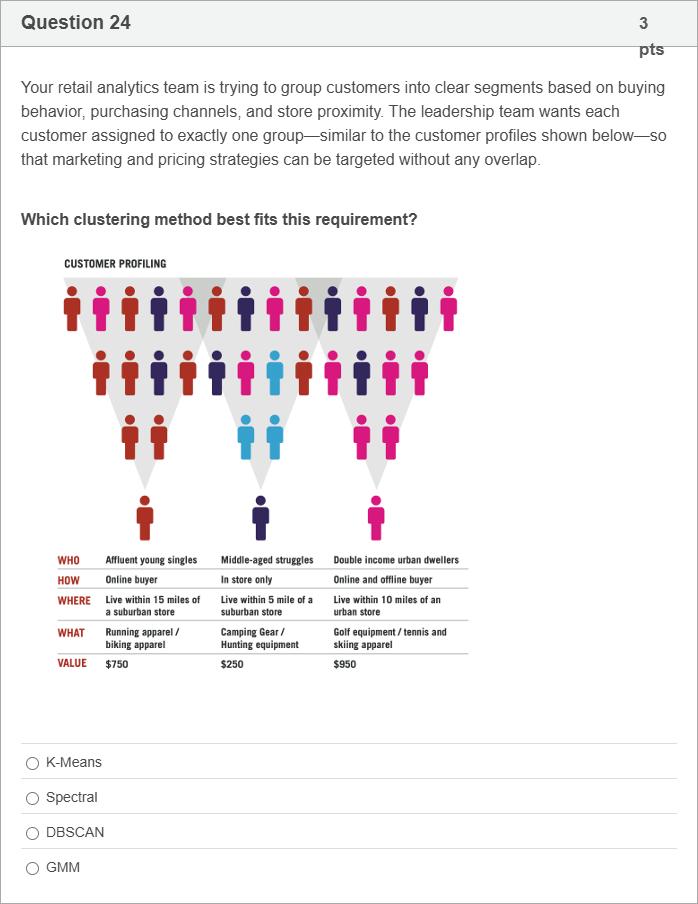
Your retail analytics team is trying to group customers into clear segments based on buying behavior, purchasing channels, and store proximity. The leadership team wants each customer assigned to exactly one group—similar to the customer profiles shown below—so that marketing and pricing strategies can be targeted without any overlap. Which clustering method best fits this requirement?
Options
A.K-Means
B.Spectral
C.DBSCAN
D.GMM
View Explanation
Verified Answer
Please login to view
Step-by-Step Analysis
The goal here is to assign each customer to exactly one group, with clear, non-overlapping segments based on buying behavior, purchasing channels, and store proximity.
Option 1: K-Means. This method partitions data into k clusters by minimizing within-cluster variance and assigns each data point (customer) to a single cluster, produ......Login to view full explanationLog in for full answers
We've collected over 50,000 authentic exam questions and detailed explanations from around the globe. Log in now and get instant access to the answers!
Similar Questions
Which of the following statements about the K-means clustering algorithm is true?
K-Means involves computing distances in input space and assigning data points to the nearest prototype points. What can one say about these prototype points? I Every cluster has its data assigned to the nearest prototype point. II They are not restricted to being data points in the training set. III They are necessarily included in the training set. IV They are usually referred to as centroids.
A retail chain wants to group its 2 million customers based on purchase behavior. Analysts consider using K-Means because they need fast runtime and easy interpretability, but the leadership team worries whether the method assumes overly simple cluster shapes. What limitation of K-Means should the team be most concerned about?
Question14 Which of the following aspects do not affect the performance of the standard k-means clustering? (you can choose more than one) Choice of initial cluster centres Probability of data samples belonging to each cluster Distribution of data samples Number of clusters ResetMaximum marks: 1.5 Flag question undefined
More Practical Tools for Students Powered by AI Study Helper
Making Your Study Simpler
Join us and instantly unlock extensive past papers & exclusive solutions to get a head start on your studies!